Hey everyone, I wanted to share some thoughts on the recent announcements from NVIDIA’s GTC conference last week – focusing on what this means for enterprise customers like you who are navigating AI deployment. Cisco had a strong showing, partnering closely with NVIDIA to roll out innovations in AI networking and security. They’re practical steps forward, and they position Cisco as a key player in making AI more accessible and secure for businesses.
“As someone who’s seen enterprises grapple with AI adoption firsthand, I appreciate how these developments address real-world pain points without overhyping the tech.”
What Was Announced and Why It Matters
Cisco unveiled a suite of AI networking innovations spanning hyperscale cloud, enterprise, and telecom environments, all built in collaboration with NVIDIA. The key highlights include
- Advancements in AI cluster management
- Ethernet-based fabrics for massive GPU scaling
- Enhanced security integrations
I’ve included a link to the full press release in my conclusion below.
For enterprises, this is about more than flashy hardware. The goal here is to solve the scalability and operational hurdles that often stall AI projects. Many organizations start small with AI but quickly hit walls when models grow or workloads multiply.
“Cisco’s updates aim to smooth that path, leveraging our networking expertise to make AI infrastructure more manageable and secure.”
I’ll dive into the specifics below, tying back to how these fit into your adoption journey.
Tackling GPU Memory Limits in Single Servers
One common roadblock in AI adoption is running out of GPU memory. You might kick off with a modest setup, but as your ambitions grow, so do the models. Take a real-world example: A cost-effective inference deployment could use Cisco UCS Servers equipped with 8x NVIDIA RTX 6000 Ada Generation GPUs. You could run multiple instances of a 120B-parameter model like a variant of OpenAI’s GPT, one per GPU. This setup maximizes throughput for inference tasks, giving you solid token throughput performance per dollar.
But what if you need to handle larger models, like DeepSeek or xAI’s Grok, which demand more memory and don’t fit on a single GPU? That’s where NVIDIA’s NVLink comes in. In a higher-end server like the Cisco C885, all GPUs are interconnected via NVLink, allowing them to pool memory effectively. This lets you run oversized models within a single server without performance cliffs. Networking remains simple – a converged fabric for northbound traffic and storage, using just a pair of ports per server. It’s a straightforward upgrade that keeps things contained and efficient, reflecting Cisco’s focus on modular, enterprise-grade AI hardware that’s easy to manage.
Scaling Across Servers: The Backend Fabric Challenge
Things get trickier when a model exceeds single-server capacity or when you’re fine-tuning, which often requires aggregating GPUs across multiple machines. Enter the backend (east-west) GPU fabric. This is essentially a high-speed network dedicated to inter-GPU communication, enabling RDMA (Remote Direct Memory Access) for low-latency data transfers.
Practically, this means adding up to 8 extra network ports/cables per server-one per GPU-to bypass unnecessary hops through the PCIe root complex that can introduce latency and break RDMA. These high-end setups use GPUDirect RDMA to allow NICs direct access to GPU memory.
For a modest 96-GPU cluster – say, 12 servers totaling 96 Rack Units (RU), you’ll need to add 6 switches (2 leaf, 4 spine for 12 RU) and 144 cables in total (96 leaf cables plus 48 spine cables). If your data center is limited to 60KW per rack, as many older data centers are, you’ll likely implement this across three racks. Cable management is an art form – or a potential nightmare if not planned well.
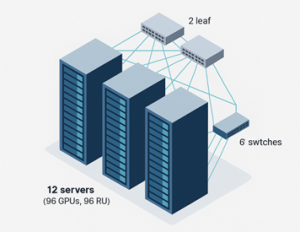
This is where enterprises often pause: The complexity can balloon costs, and so can operational overhead. But Cisco’s announcements at GTC directly tackle this, making large-scale AI more feasible without requiring a PhD in networking.
Simplifying AI Clusters with Cisco Nexus HyperFabric AI
To ease deployment, Cisco introduced Nexus HyperFabric AI, a cloud-managed solution for AI clusters. Think of it like Meraki for your AI infrastructure – auto-configured fabrics that provision switches, servers, and GPUs seamlessly, much like how Meraki handles wireless APs or cameras.
“You get a unified dashboard for monitoring and scaling, reducing setup time from weeks to hours.”
Install it into a colo facility, and you have a turnkey AI-managed cloud cluster at your disposal.
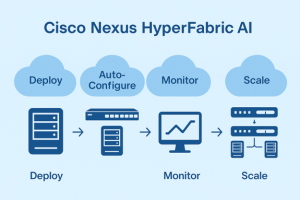
For enterprises, this means less custom engineering. If you’re building out AI for R&D or production inference, HyperFabric lets your IT team focus on value rather than plumbing. It’s really going to change the game for mid-sized adopters who want hyperscaler efficiency without the hyperscaler budget. Check out all the details on Cisco’s site.
Enterprise-Friendly Options with Nexus Dashboard and Spectrum-X
Not everyone wants full cloud management – some prefer on-prem control. For those, Cisco has licensed NVIDIA’s Spectrum-X AI Ethernet platform and integrated it into our Silicon One-based switches. This brings advanced AI load balancing and congestion control to Cisco hardware, allowing your existing network admins to deploy AI fabrics using familiar tools like Nexus Dashboard.
We’ve validated this in enterprise reference architectures, covering everything from small pods to larger 1024 GPU clusters.
“It’s about leveraging what you already know: If your team runs Cisco networks today, they can handle AI tomorrow.”
This ties back to Cisco’s strength in enterprise IT – making AI an extension of your current stack, not a rip-and-replace.
For Hyperscalers and Multi-Tenant Environments: NVIDIA Cloud Platform Certification
On the hyperscale side, Cisco announced Nexus switches running on NVIDIA’s Spectrum silicon, certified for the NVIDIA Cloud Platform (NCP). This enables massive, multi-tenant AI clusters with thousands of GPUs, all managed via Cisco’s OS and dashboard. For service providers or large enterprises with siloed teams, it means secure, isolated environments at scale.
This is huge for telecom and cloud operators, but even enterprises can benefit if you’re outsourcing to NCP-certified providers or require Cisco’s pedigree in secure multi-tenanted networks. It underscores Cisco’s role in bridging enterprise and hyperscale worlds.
Bolstering AI Security with Cisco AI Defense and NVIDIA NeMo Guardrails
Security can’t be an afterthought in AI. Earlier this year, Cisco launched AI Defense, which discovers shadow AI usage by scanning cloud environments (via Cisco Multi-Cloud Defense) for LLM API calls across AWS, Azure, or GCP. It maps vulnerabilities to frameworks like OWASP or MITRE ATLAS, using tech from our Robust Intelligence acquisition for AI-specific red-teaming. You can even remediate issues, like blocking detected PII leaks.
At GTC, Cisco announced that we extended this to on-premises environments with AI Defense on Cisco AI PODs. It’s a hybrid model, managed from Cisco’s cloud console but pointed at your private endpoints for red-teaming local models. Read the full reference architecture here.
For runtime protection, AI Defense deploys guardrails directly on your Kubernetes cluster, running alongside LLMs. This ties into NVIDIA’s NeMo Guardrails, announced in our integration blog. NeMo lets you chain tools like Meta’s Llama Guard for content moderation or NVIDIA’s jailbreak detectors into a pipeline.
Plus, instead of just dropping risky traffic (which kills user experience), AI Defense offers an API for your apps. Call it from your chatbot code to get feedback on violations – e.g., “Avoid sharing sensitive data” – and display friendly errors. No app rewrites needed for basic blocking, but the API elevates UX.”
For fine-tuned models, which are 3x more susceptible to jailbreaks and 22 times more likely to produce harmful responses, route them through this service like it’s an antivirus for AI.
“In my experience at Cisco, this hybrid approach helps enterprises balance innovation with compliance. We’re not claiming perfection, AI threats evolve fast, but these tools make security proactive.”
Wrapping Up – Cisco’s Practical Path Forward
Cisco’s GTC announcements aren’t revolutionary hype. Instead, they’re evolutionary fixes for enterprise AI challenges. From simplified fabrics via HyperFabric and Spectrum, plus on-prem security with AI Defense and NeMo integrations, we’re making AI more deployable and safe. As Cisco continues to lead in networking, these tie directly into our ecosystem, helping you adopt AI without reinventing your infrastructure.
For a look into the suite of AI networking innovations Cisco unveiled at GTC, this press release covers everything. If you’re an enterprise adopter, start with our reference architectures or reach out – I’m happy to chat. What’s your biggest AI hurdle right now? Let me know in the comments, and let’s discuss it further.
#CiscoAI #CiscoSecurity #EnterpriseAI #AIInfrastructure



